Здравствуйте! Нередко для пользователей Зеброида стоит вопрос о больших объемах контента. Предлагаю один из способов решения.
Мы будем вытаскивать полные статьи из rss-фида с помощью
данного продукта.
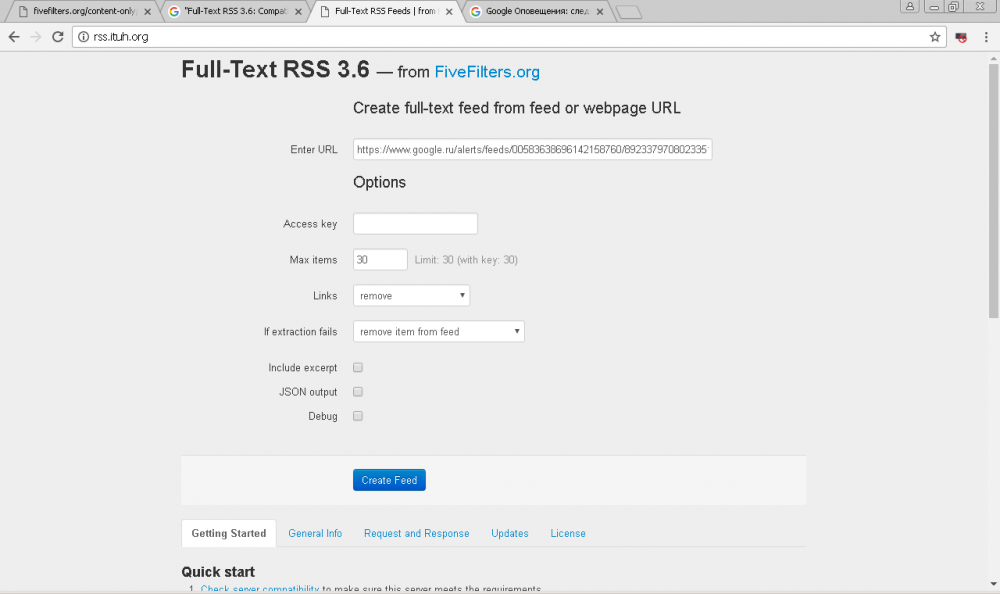
Для этого вводим в строке поиска Google запрос типа: «Full-Text RSS 3.6: Compatibility Test».

Пробегаемся по выдаче. Важно, чтобы требуемые разработчиком технические характеристики совпадали с возможностями серверов, на которых установлен данный скрипт. К примеру, на
этом сайте все требования соблюдены.
Переходим на главную страницу скрипта и настраиваем его:

- Напротив «Max items» вводим 30 (используем предоставленный нам лимит). Скрипт будет выдергивать 30 полных статей.
- Напротив «Links» выбираем «remove». Скрипт будет удалять ссылки из статей.
- Напротив «If extraction fails» выбираем «remove item from feed». Скрипт будет пропускать статьи, где не удалось выдернуть контент полностью.
С поиском RSS-фида заморачиваться также не будем и воспользуемся сервисом google Alerts.

Ну тут, я думаю, пояснять не нужно. Наверное уже все сталкивались с этим сервисом.
После создания RSS-фида копируем ссылку на него. И скармливаем эту ссылку нашему скрипту. Вот что в итоге получается:

Из адресной строки копируем ссылку. Мы ее будем в дальнейшем использовать в зеброиде. Открываем Зеброид. Выбираем «Проект — Импорт — RSS Импорт».

Вводим наш URL-ленты и запускаем процесс.
Затем нам надо сделать небольшие правки. Для этого выбираем «Обработка текстов — Замена». И создаем 3 правила:

Применяем эти три правила.
Теперь нам нужно удалить ненужные тэги. Выбираем «Плагины — Работа с текстом — HTML Cleaner».
Указываем тэги, которые мы хотим оставить и запускаем процесс.
Также неплохо было бы немного уникализировать добытый контент. Для этого выбираем «Обработка текстов — Синонимайзер».

Указываем процент и запускаем процесс.
Ну вот вроде бы и все!

Ну а дальше используйте этот контент по своему усмотрению. Надеюсь, что кому-то помог. Спасибо за внимание!