
Проект:
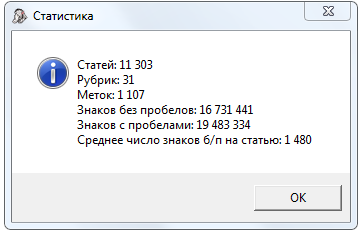
Запустил поиск дублей статей и Зеюроид задумался на долго, оставил его на ночь и в общей сложности он искал дубли около 9-10 часов в это время на компе ничего не было запущено, приоритет Зеброиду стоял высокий.
Смотрел статистику нагрузки на CPU и как я понял, то используется только одно ядро так как у меня было нагружено только одно ядро и оставшиеся 3 стояли почти без дела. Может я и ошибаюсь но мне кажется, что работать с многоядерными процессорами Зеброид не умеет? + я бы с удовольствием отдал на выполнения задач Зеброидом гораздо больше ресурсов чем он берет на работоспособности компа это не отразится даже если потребление ресурсов увеличится в 2 раза.
С вводом возможности верстать сразу несколько сайтов в одном проекте встает вопрос о производительности, думаю его нужно решать так как теряется сама идея верстки нескольких сайтов в одном проекте.